¡Hola! que os parece si seguimos viendo cursos de Learning SAP y vemos el curso de Overview SAP Datasphere, para poder comenzar y entender como es SAP Datasphere. No hace mucho escribí sobre la introducción a SAP Datasphere que podéis ver aquí. Pero en este caso lo que vamos a ver es como es el curso que nos ofrecen. Comenzamos y lo vemos???
Vamos a ver cada parte en las actualizaciones del lanzamiento Q4.2025 de SAP Analytics Cloud (SAC). Veremos cómo estas novedades no son solo cambios estéticos, sino transformaciones profundas que mejoran y redefinen la experiencia de usuario y potencian la planificación estratégica. ¡Vamos a verlo!
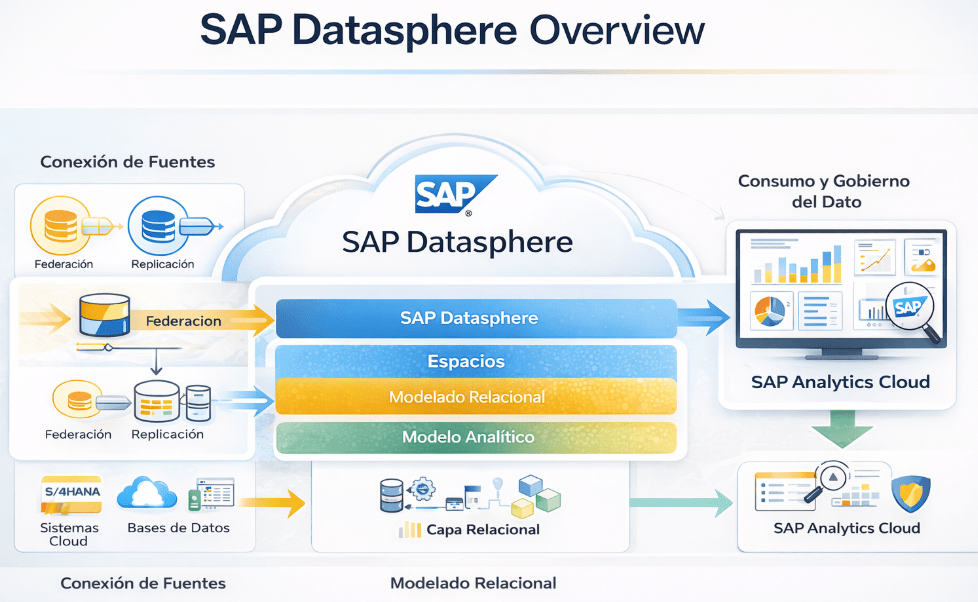
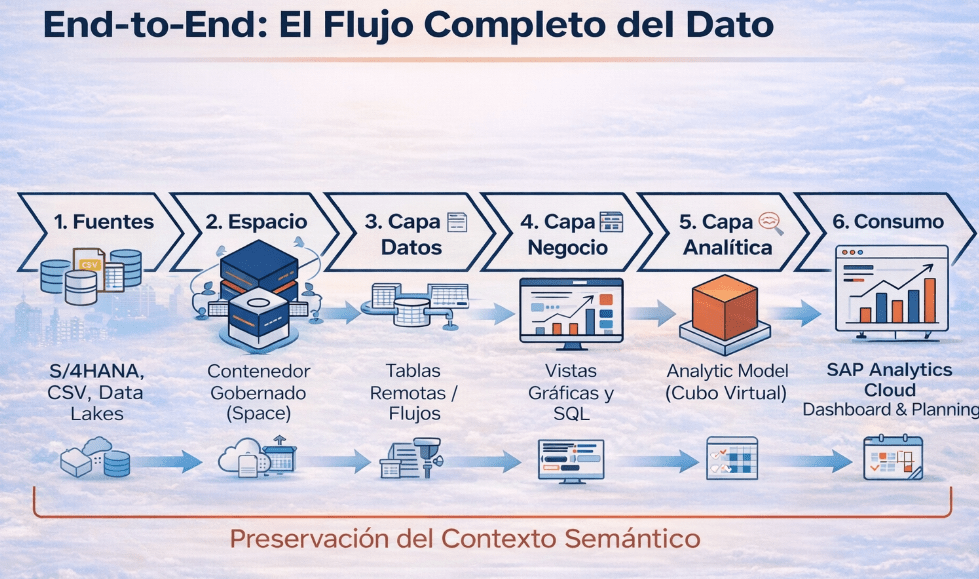
SAP Datasphere de principio a fin: Siguiendo la ruta del dato
Vamos a intentar entender de verdad el potencial de SAP Datasphere, para esto tenemos que cambiar el enfoque, no podemos entender que es un conjunto de herramientas aisladas, sino de un flujo de datos completo, de principio a fin.
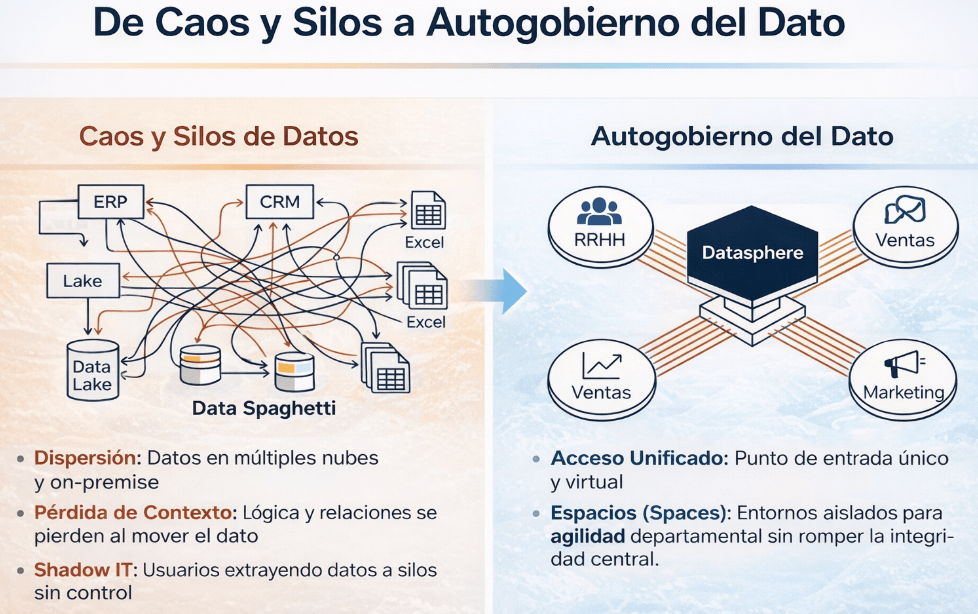
Durante años, como hemos ido viendo con la experiencia, los datos en las empresas han sido un «pequeño caos» que muchos llaman «Data Spaghetti»: datos dispersos en sistemas on-premise, Excel y no puede faltar «nubes», con integraciones frágiles que pierden el contexto de negocio por el camino. SAP Datasphere nos lo presentan como la evolución hacia un Business Data Fabric, una arquitectura que busca poner orden en este «pequeño caos».
El verdadero valor de DSP no reside en una funcionalidad concreta, sino en su capacidad para unificar el acceso a todos esos datos, preservando la lógica de negocio desde que el dato entra o se «virtualiza» hasta que se visualiza en un informe. Vamos a seguir esa ruta para entender la lógica que hay detrás de DSP.
1. El punto de partida: ¿Cómo entran los datos?
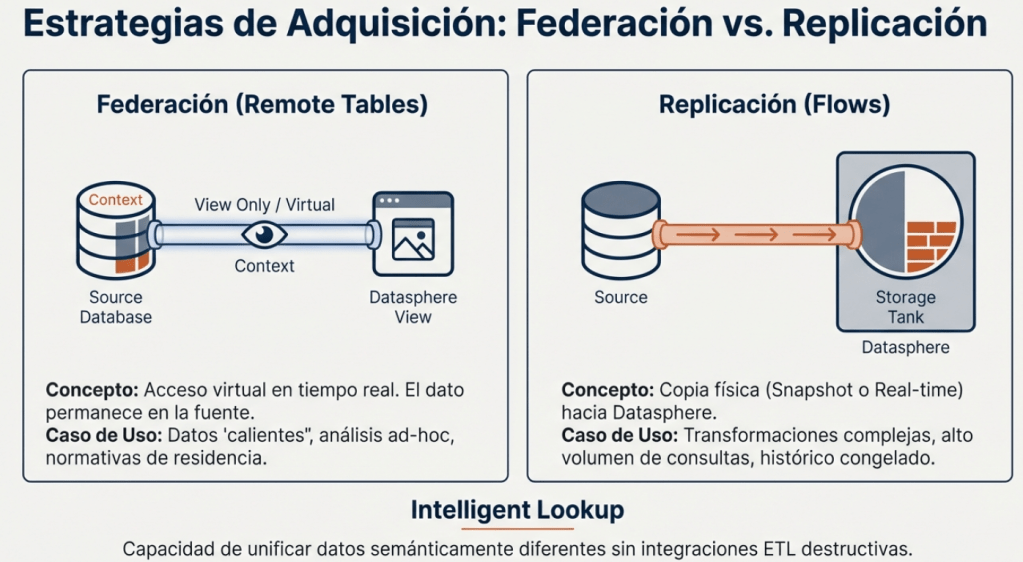
Todo proyecto de datos comienza conectando las fuentes. SAP Datasphere está diseñado para integrarse tanto con el ecosistema SAP (S/4HANA, BW/4HANA…) como con sistemas externos (Hyperscalers como AWS o Google, Data Lakes, etc.). Para esto, nos ofrece dos estrategias principales de adquisición, y elegir la correcta es una de las primeras decisiones de arquitectura clave.
• Federación (Remote Tables): Esta estrategia consiste en un acceso virtual al dato en tiempo real. La información permanece en su sistema de origen y SAP Datasphere actúa como un intermediario que la consulta cuando es necesario. Es ideal para datos «calientes» que deben estar siempre actualizados, para análisis ad-hoc donde no queremos mover grandes volúmenes, o cuando normativas de residencia de datos nos impiden moverlos de su ubicación original.
• Replicación (Flows): Aquí sí realizamos una copia física del dato, que se traslada y almacena en SAP Datasphere. Esta copia puede ser un snapshot (una foto en un momento concreto) o una réplica en tiempo real. Se utiliza cuando necesitamos realizar transformaciones complejas, cuando el sistema origen no soportaría un alto volumen de consultas o cuando queremos congelar un histórico para análisis.
Vamos a por un ejemplo para entenderlo un poco mejor, de forma sencilla, la federación es como ver un partido en directo por streaming, mientras que la replicación es como grabarlo en tu disco duro para verlo (y editarlo) después.
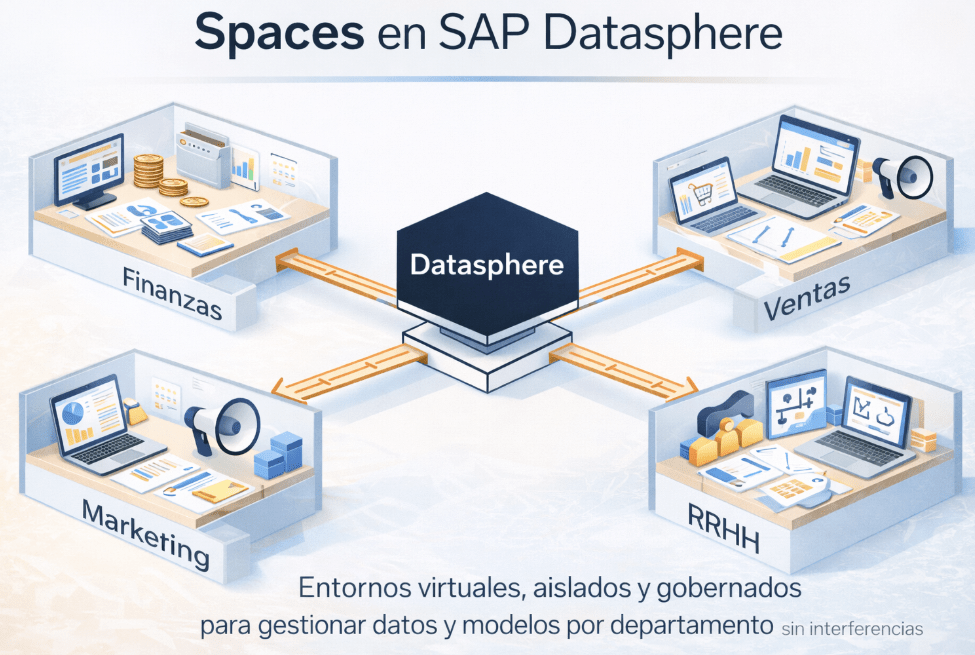
2. Ordenando la casa: El Space como dominio de datos
Una vez conectamos las fuentes, algo muy muy importante en todo proyecto, el trabajo se organiza en Spaces. Y que es un Space??? Un Space lo podemos definir como un contenedor principal y entorno de trabajo dentro de SAP Datasphere. Funciona como un entorno virtual, aislado y gobernado, que permite a diferentes equipos o departamentos (Finanzas, Ventas, Marketing, RRHH) gestionar sus datos, modelos y conexiones sin interferir con los demás.
Este concepto es la respuesta directa al problema de los silos de datos. SAP Datasphere funciona como un modelo «Hub-and-Spoke», es el punto de entrada único y centralizado (el hub), mientras que los Spaces son los entornos departamentales (spokes). El resultado es que se potencia la autonomía de los departamentos sin sacrificar el gobierno central, resolviendo así el clásico dilema de BI entre «control vs. agilidad».
De forma sencilla para que lo podamos entender un poco mejor, podríamos imaginarlo como un gran taller de fabricación donde cada equipo tiene su propio banco de trabajo independiente, con sus herramientas y materiales. Lo que hagan allí no afecta al resto, a no ser que decidan compartir una pieza terminada con los demás.
3. Construyendo los cimientos: El modelado relacional
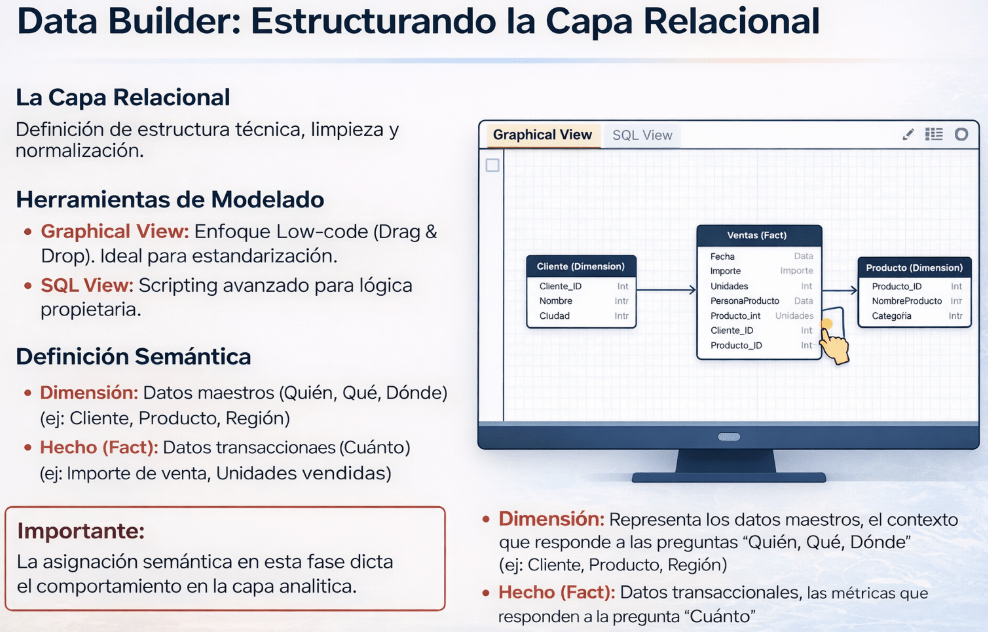
Dentro de nuestro Space, la primera parada es la Capa de Datos (Data Layer). Podríamos pensar que aquí es donde entran los «ingenieros de datos», como el post anterior decimos que es la «cocina» donde se preparan los ingredientes crudos. Aquí es donde tendremos que definir la estructura técnica, se limpian los datos y se normalizan para asegurar su calidad.
Para esto, en esta fase, usamos es el Data Builder, que permite modelar de dos maneras:
• Graphical View: Un enfoque Low-code (Drag & Drop). Ideal para estandarizar.
• SQL View: Para los casos que requieren una lógica más avanzada o específica, permite escribir código SQL directamente.
En esta fase se crean dos tipos de objetos semánticos fundamentales:
• Dimensión: Representa los datos maestros, el contexto que responde a las preguntas «Quién, Qué, Dónde» (ej: Cliente, Producto, Región).
• Hecho (Fact): Contiene los datos transaccionales, las métricas que responden a la pregunta «Cuánto» (ej: Importe de venta, Unidades vendidas).
Esta asignación semántica inicial es el primer paso crucial en la preservación del contexto de negocio. No estamos simplemente definiendo tablas; le estamos diciendo a SAP Datasphere lo que los datos significan. Esto dictará por completo el comportamiento del dato en las capas superiores.
4. Del dato técnico al significado: El paso al modelo analítico
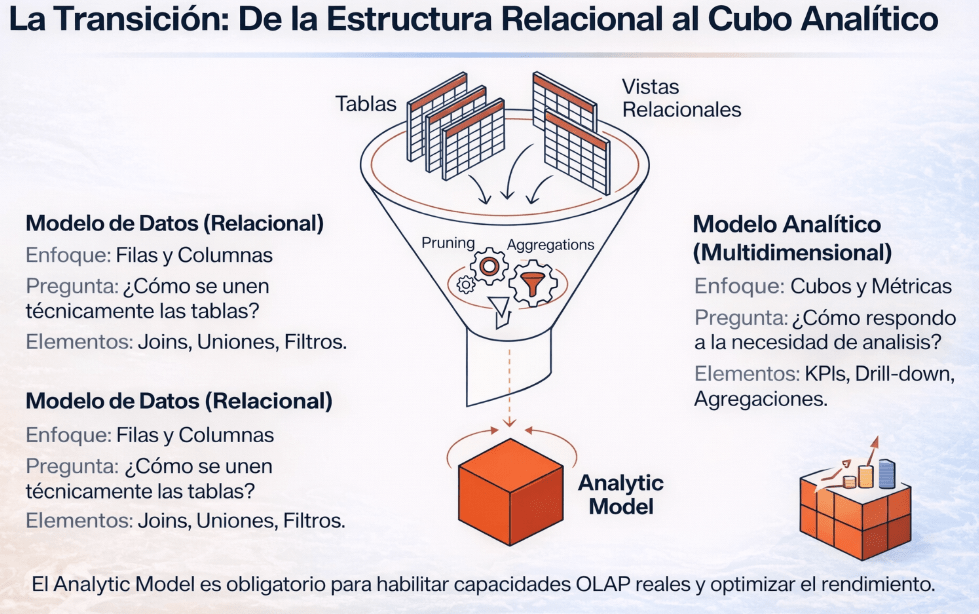
Una vez que tenemos la base relacional construida, damos el salto a la capa analítica. Este paso lo podemos visualizar como un embudo: tomamos las múltiples tablas y vistas técnicas de las capas de datos y, mediante procesos de optimización como el Pruning y las Aggregations, las transformamos en un único cubo analítico, enfocado y optimizado para el negocio.
La diferencia de propósito entre ambos modelos es clave, y es la base de una arquitectura de datos moderna y resiliente. Esta separación de capas evita la fragilidad de los sistemas BI tradicionales, donde un cambio en una tabla origen rompía el informe final. Aquí se separan las responsabilidades del ingeniero de datos y del analista de negocio.
• Modelo Relacional: Su enfoque es de Filas y Columnas. Responde a una pregunta técnica: «¿Cómo se unen las tablas?». Su lenguaje es el de los Joins, uniones y filtros.
• Modelo Analítico (Multidimensional): Su enfoque es de Cubos y Métricas. Responde a una pregunta de negocio: «¿Cómo respondo a una necesidad de análisis?». Su lenguaje es el de los KPIs, el drill-down y las agregaciones.
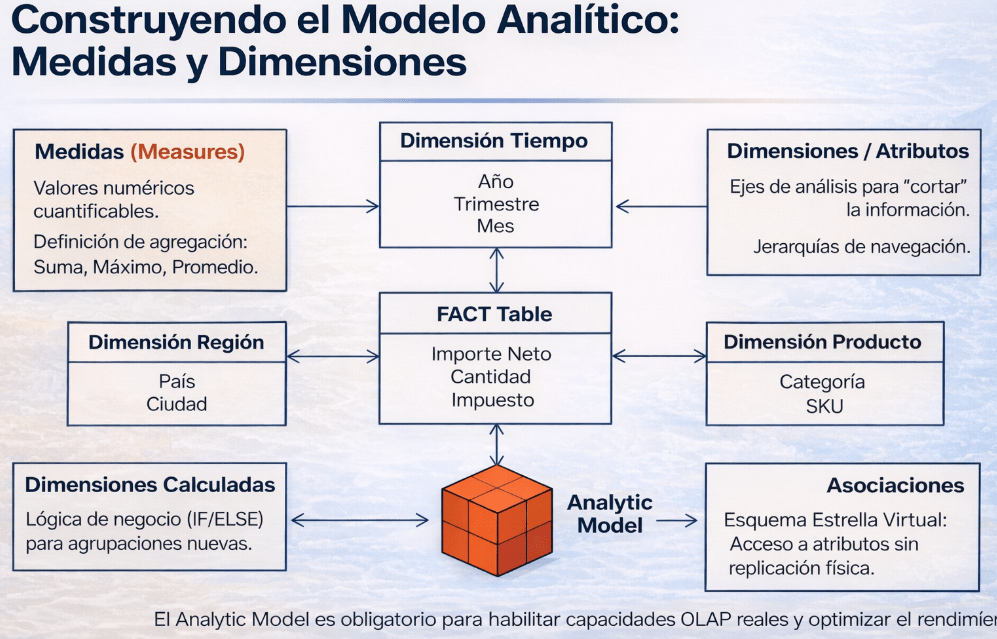
El Analytic Model es el objeto final de esta fase y es obligatorio para el consumo en herramientas de reporting como SAP Analytics Cloud. Es este modelo el que habilita las capacidades OLAP (navegación, jerarquías, etc.) y garantiza un rendimiento óptimo en las consultas. Es aquí donde el contexto semántico preservado se vuelve realmente potente, exponiendo los datos de una forma que el negocio entiende de forma nativa. Sus componentes clave son las Medidas (Measures), que son los valores cuantificables (Importe Neto, Cantidad), y las Dimensiones, que son los ejes por los que analizamos esas medidas (Tiempo, Región, Producto).
5. La visualización: Consumo en SAP Analytics Cloud
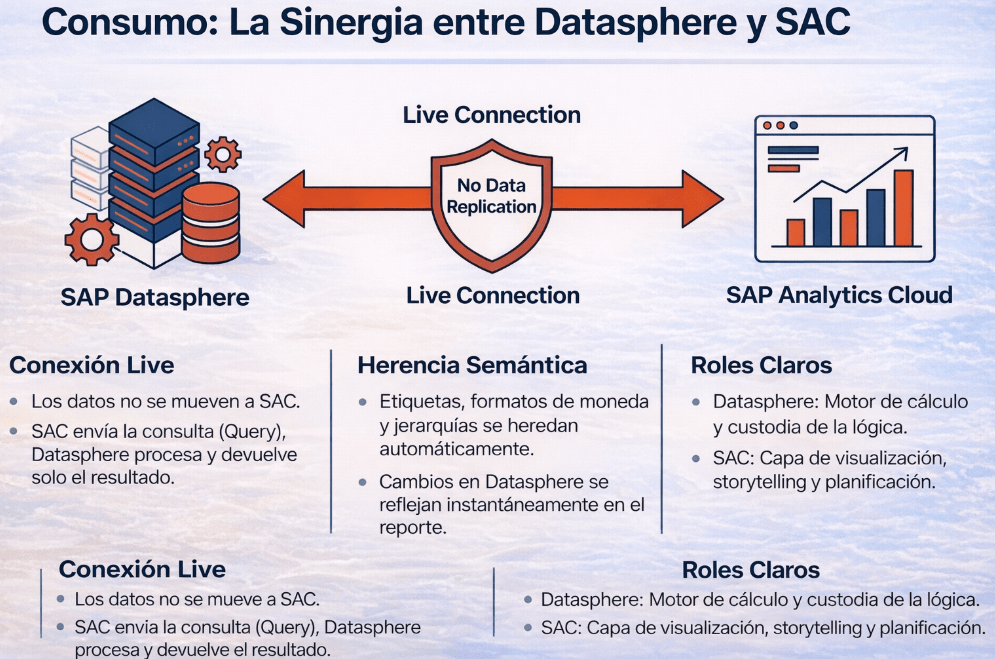
SAP Datasphere y SAP Analytics Cloud (SAC) van de la mano. La integración entre ambas es nativa y se basa en el concepto de Live Connection.
Esto significa que los datos nunca se mueven ni se replican en SAC. Cuando un usuario abre un informe en SAC, la herramienta envía una consulta a SAP Datasphere. Este, que es el motor de cálculo, procesa la petición y devuelve únicamente el resultado agregado. Esto no solo es eficiente, sino que garantiza que los cambios en SAP Datasphere se reflejan instantáneamente en el reporte.
Además, existe una ventaja fundamental: la Herencia Semántica. Este es el resultado final de haber preservado el contexto de principio a fin. Todas las etiquetas de negocio, los formatos de moneda, las jerarquías y las descripciones que definimos en el Analytic Model se heredan automáticamente en SAC. La lógica de negocio se define una vez en SAP Datasphere y se garantiza su consistencia en cualquier lugar donde se consuma.
Los roles quedan perfectamente definidos:
• SAP Datasphere: Es el motor de cálculo y el custodio de la lógica de negocio.
• SAC: Es la capa de visualización, storytelling y planificación.
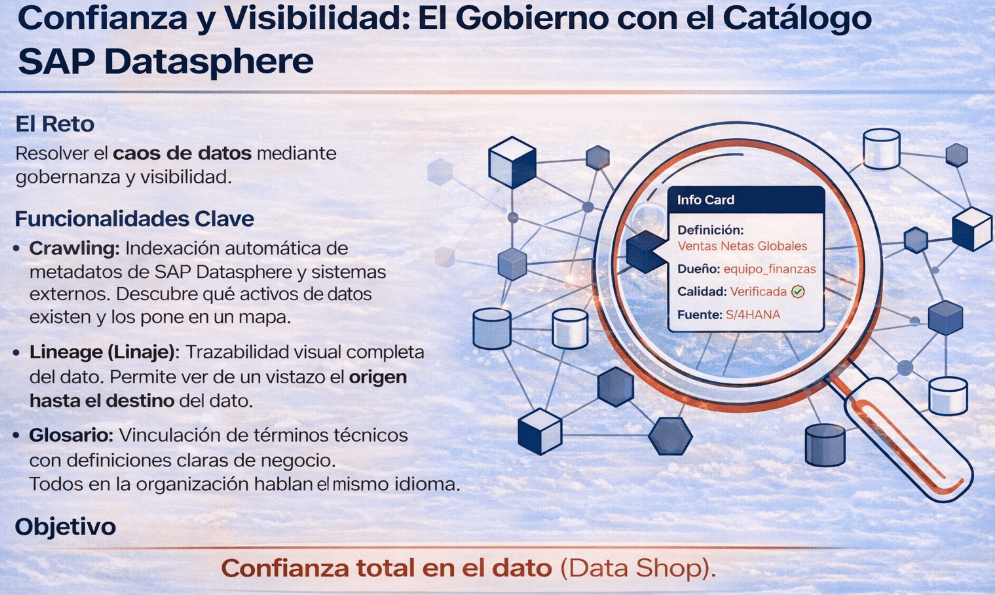
6. Confianza y visibilidad: El gobierno con el Catálogo
Para cerrar el ciclo y no menos importante, asegurando que todo este flujo no se convierta en otro silo de datos, SAP Datasphere incluye el Catálogo. Esta herramienta está diseñada para resolver el caos de datos mediante gobernanza y visibilidad.
Sus funcionalidades clave se pueden resumir en tres puntos:
• Crawling: Realiza una indexación automática de todos los metadatos de SAP Datasphere y de sistemas externos para descubrir qué activos de datos existen y ponerlos en un mapa.
• Lineage (Linaje): Ofrece una trazabilidad visual completa del dato. Permite ver de un vistazo de dónde viene un KPI (origen) y dónde se está utilizando (destino), desde la tabla fuente hasta el informe final en SAC.
• Glosario: Permite vincular los activos técnicos con definiciones de negocio claras y validadas. De esta forma, todos en la organización hablan el mismo idioma y entienden lo que significa, por ejemplo, «Ventas Netas Globales».
El objetivo final del Catálogo es generar confianza total en el dato, facilitando su descubrimiento y consumo a través de un «Data Shop» interno, una tienda de activos de datos fiables y listos para usar.
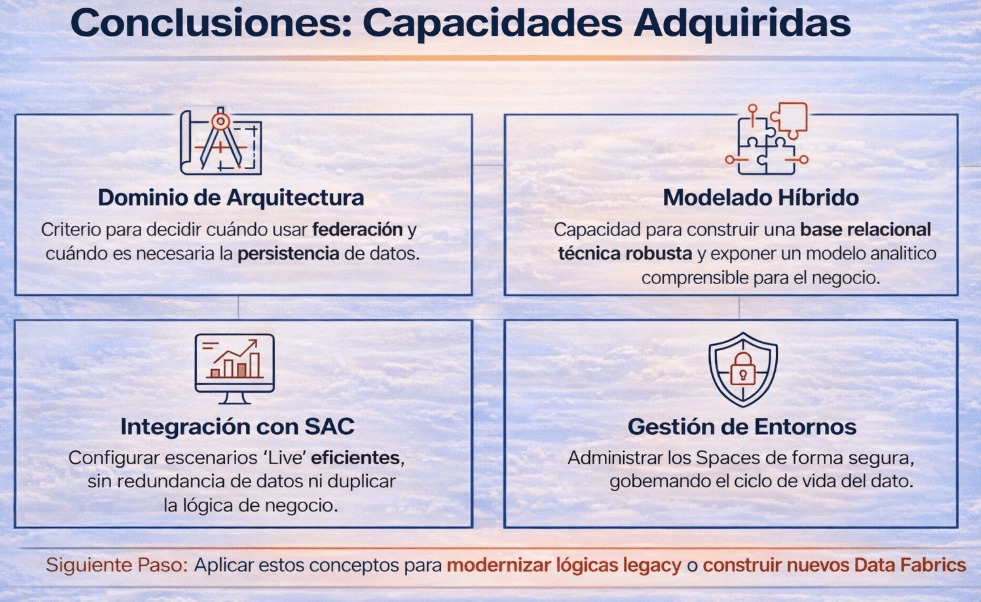
7. ¿Qué te llevas realmente de este flujo?
Con este curso vamos a poder entender este recorrido de principio a fin no es un ejercicio teórico. Es nuestra base para desarrollar las capacidades que realmente importan a la hora de trabajar con SAP Datasphere. No se trata de memorizar botones, sino de adquirir criterio.
Al comprender este flujo, desarrollas competencias clave:
• Dominio de Arquitectura: El criterio para decidir cuándo tiene sentido usar federación y cuándo es necesaria la persistencia de datos.
• Modelado Híbrido: La capacidad de construir una base relacional técnica robusta y, sobre ella, exponer un modelo analítico comprensible para el negocio.
• Integración con SAC: La habilidad para configurar escenarios ‘Live’ de forma eficiente, sin crear redundancia de datos ni duplicar la lógica de negocio.
• Gestión de Entornos: El conocimiento para administrar los Spaces de forma segura, gobernando el acceso y el ciclo de vida del dato.
Espero que os sirva
